


ChinAI #102: Lip Reading "The Bad Kids" -- Lip Recognition Tech Applied to Hit Chinese Drama
Plus, Financial Transparency for Year 1 of Paid Subscriptions
Greetings from a land where translations are living breathing things…
Very grateful to all the people who engaged with last week’s translation on tech neutrality — shout out to Kohzy Koh and James Bradbury for some exhaustive fact-checking and editing. Many readers also took on the translation challenge for the really tough paragraphs on Chinese views of science & tech in the second half of the 19th century. Thanks to Yishu Mao, Brayden Mclean, and Ryan Soh for sharing their translations (p. 6 of last week’s translation).
…as always, the archive of all past issues is here and please please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors).
Feature Translation: Lip Reading “The Bad Kids”
In the last few weeks a Chinese web drama about three children who accidentally film a murder, titled “The Bad Kids” (隐秘的角落), has caught fire. Here’s Sixth Tone on the rave reviews it has drawn:
“Crouching Tiger, Hidden Dragon” star Zhang Ziyi on Thursday praised the show as one of the first Chinese dramas she’s seen that rivals American and British productions in terms of quality. On IMDb-like review platform Douban, “The Bad Kids” has an impressive aggregate rating of 8.9 out of 10 based on over 440,000 reviews.
CONTEXT: This week, we translate a blog post from a fan of the series, Eury Chen, who dug into why there were certain lines from the episodes that had to be modified in order to pass China’s review process for TV dramas. They applied lip-reading AI to restore the original lines of dialogue:
“Two days ago, I watched the TV series "The Bad Kids" in one go, and the plot was quite exciting. The disadvantage is that in order for the series to pass the review (of the National Radio and Television Administration), the edited sequences for episodes 11 and 12 were disrupted, even to the point that lines were modified, so that there are several places in the film where the actor's mouth movements and lines are not matched, which makes the plot confusing to people. Therefore, I tried to restore the modified lines through artificial intelligence technology, thereby restoring some of the original plot, which contained a darker truth.”
KEY TAKEAWAYS:
Eury’s lip-reading process:
1) Find places where the actors’ lip movements do not match up with the actual dialogue (mainly in the last episode)
2) Use the facemesh model (a package in TensorFlow) to obtain features of facial expressions (image below) to predict the the initial of a Chinese syllable (声母 -- usually a consonant like b in bao 抱) and the final of a Chinese syllable (韵母 -- i.e. the syllable other than the initial, so like -ao in bao 抱).
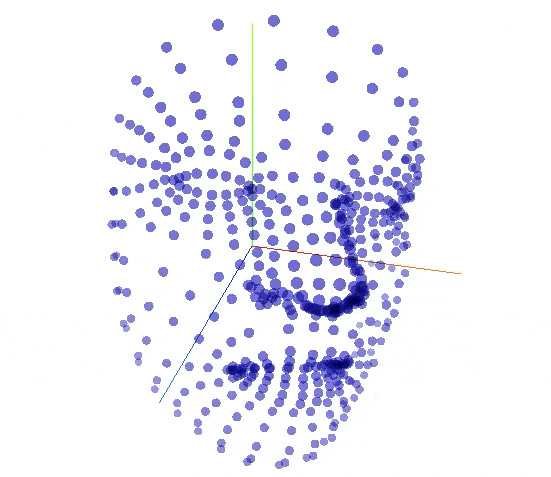
3) Try to find the best match between the choices of pinyin* and the context clues in the plot. It is too difficult to predict Chinese characters directly through the shape of the mouth.
*system of transcription for Mandarin Chinese sounds (e.g. bao for 抱)
Why did the censors modify the dialogue?
Eury explains that the original dialogue violated two of the most important principles in the review process of Chinese dramas: 1. No unsettled cases; 2. Bad guys must be brought to justice.
An example of the original dialogue and post-censor modifications (the original Mandarin has GIFs that show the exchange). Note how the original dialogue conveys Zhu Chaoyang, one of the boys who witnessed the murder, in a much darker light:
MODIFIED Yan Liang: "Tell the police" 「告诉警察吧」
---> ORIGINAL = Yan Liang: “What now?” [那该怎么办]
MODIFIED Zhu Chaoyang: "As my dad hoped" 「像我爸希望的那样 」
---> ORIGINAL = Zhu Chaoyang: “Apart from having him* get caught...”「除非让他被抓...」*him refers to the substitute teacher they filmed murdering his elderly in-laws
MODIFIED Zhu Chaoyang: "Do you want to call the police?" 「你想报警么」
----> ORIGINAL = Zhu Chaoyang: “Don’t you want to get revenge?” 「你不想报仇么」 --- one of the pinyin outputs from the lip-reading algorithm: ni bu xiang bao chou me
Broader implications:
As Jack Clark has written in previous issues of ImportAI, lip-reading has a broad range of uses, including assistance for the deaf or hard-of-hearing, advertising, but also surveillance. In October 2018, the Chinese Academy of Sciences and Huazhong University of Science and Technology, which the researchers claim is “currently the largest word-level lipreading dataset and the only public large-scale Mandarin lipreading dataset.” The TV theme returns in this case as well, since the dataset was built by annotating Chinese TV shows.
FULL TRANSLATION: Lip Reading the Bad Kids
Financial Transparency for Year 1 of Paid Subscriptions
About a year ago on July 7, I launched the paid subscriptions option for ChinAI. The promise was that subscriptions would go toward compensating ChinAI contributors for their translation work and expert analysis. In that post I also committed to donating 10% of any earnings to GiveWell. Thank you so much to all the subscribers — very cool to have 150+ folks financially invested in this community. You can join them by subscribing here.
Here’s the financial breakdown from this past year. Net revenue after Stripe and Substack took their cut was $6756.45 (screenshot below from my Stripe account):

For contributors and translators, I paid out $1550 to 13 people (some of whom generously donated their time). Taxes and other expenses brought me down to a net income of under $5000 for the year of paid subscriptions. So I donated 10% of that to GiveWell, which aims to direct donations to effective charities.

Anyways, just trying to shine a little bit of sunlight on how I’m taking care of my tiny little piece of land amidst the vast Internet. Thanks to everyone who’s helping it grow.
ChinAI (Four to Forward)
Must-read: 5 Takeaways from China’s Draft Data Security Law
Samm Sacks, Qiheng Chen, and Graham Webster digest five important developments in the draft law. It’s a really impressive piece that combines 1) distillation of a lot of complicated legal jargon, context from historical thorny issues in data security, 2) insights from key Chinese scholars and standards drafters working on these issues, 3) balanced and concise analysis, which avoids hype-chasing.
“The formation of a data classification system at the national level that would delineate different types of data for different treatment under various laws and regulations” — relates to forthcoming work on an “important data” standard.
Seeks to define a procedure “to specify how the state (e.g., the Ministry of State Security, the Ministry of Public Security, etc.) lawfully may access data from private sector platforms.”
Could be “the first national law that recognizes and even calls for the establishment of data transaction markets.”
Tries to address bureaucratic turf battles by clarifying jurisdiction on data protection
Tackles cross-border flows of data, including export controls on data and codifying reciprocity on “discriminatory” treatment of Chinese businesses.
Should-read: Balancing Standards — US and Chinese Strategies for Developing Technical Standards in AI
Unpacking a few thoughts on my recent commentary for the National Bureau of Asian Research on the importance of technical standards in US and Chinese AI development.
First, the two NBR reports on standards that have really stood the test of time and are still essential overview of China’s approach to standards-setting are Kennedy et al. 2008 and Yao and Suttmeier 2004. You have to pay to read them I believe, but it’s well worth it.
One of the things I wanted to work through was clarifying what is meant by “standards” — something that’s still a work in progress. I discuss 1) technical standards as int’l private standards (e.g. via bodies like the ISO/IEC); 2) int’l public standards (e.g. via intergovernmental organizations like the ITU — though these bodies are becoming more and more privatized); and 3) domestically-oriented government efforts to provide measurements, specifications, and benchmarks (which are also often discussed in the language of “standards). For example, NIST’s facial recognition vendor test helps establish certain benchmarks for evaluating algorithmic accuracy. Sometimes these become incorporated into an international technical standard down the line.
Main point I want to get across that technical standardization involves a broad balance of different interests, beyond the narrow IP/competitiveness concerns that dominate existing discussions. In particular standards are important vehicles of international private regulation, and they will play an important role in AI governance.
Should-read: Thread on Douyin content monitoring process
Isabelle Niu provides a window into how Bytedance (owns Douyin & TikTok) regulates livestreaming content based on their detailed 2019 report. This process involves real-name registration + facial recognition (to prevent foreigners from borrowing Chinese IDs to register), coordination between AI systems and humans to do real-time monitoring of livestream content, etc.


Should-read: Turbocharged China Chip Investments Spark Bubble Fears
For Reuters, Josh Horowitz and Samuel Shen give an informative update on soaring valuations ofr Chinese chip-related companies. Prior to reading this article, if you asked me about a promising Chinese AI chip company, Cambricon would have been one of the first companies I listed. Here’s an interesting nugget that caused me to update my priors: “Cambricon, an AI chip company set to list on the STAR market this year, in its prospectus said it booked revenue of 444 million yuan in 2019 and a net loss of 1.18 billion yuan. After losing business with Huawei, Cambricon now earns almost half of its revenue from a single municipal government branch.”
Thank you for reading and engaging.
These are Jeff Ding's (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is a PhD candidate in International Relations at the University of Oxford and a researcher at the Center for the Governance of AI at Oxford’s Future of Humanity Institute.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Any suggestions or feedback? Let me know at chinainewsletter@gmail.com or on Twitter at @jjding99