


ChinAI #261: First results from CAICT's AI Safety Benchmark
The China Academy of Information and Communications Technology aims to develop an authoritative AI Safety Benchmark
Greetings from a world where…
it truly is the golden age of nerd TV (trying to keep up Three Body Problem, Shogun, and Fallout!)
…***Thanks folks for getting the paid subscriptions back up a bit in the past few weeks; please consider subscribing here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors). As always, the searchable archive of all past issues is here.
Feature Translation: Authoritative large model AI Safety Benchmark first round results officially released
Context: Over the past few months, many of our ChinAI translations have pinpointed the lack of a comprehensive and consistent evaluation system for AI safety and security as one of the barriers to China’s AI governance efforts. The “Blue Paper Report on Large Model Governance” (ChinAI #246) identified the China Academy of Information and Communications Technology’s (CAICT) large-model safety benchmarks as one important initiative to fill this gap (Note: CAICT is a government-affiliated think tank under China’s Ministry of Industry and Information Technology). Last week, CAICT released the first round of results from its AI safety benchmark, which evaluated eight models on 7,343 test questions. H/t to the one and only Matt Sheehan for flagging this.
Key Takeaways: Let’s start with the Who.
CAICT worked with 17 other groups to jointly launch this benchmark. Most notable among this group is China’s Artificial Intelligence Industry Alliance (AIIA), which has established a safety/security governance committee to work on related issues. For more details, see this CSET primer on China’s AIIA.
For this initial round of evaluations, quarter one of 2024, CAICT selected eight models. Model developers in brackets:
Qwen1.5 (72B) [Alibaba]
360gpt-pro (70B) [360 total security, formerly Qihoo 360]
ChatGLM3 (6B) [ZhipuAI and Tsinghua University]
BaiChuan (13B) [Baichuan AI]
Sensechat-32K (70B) [SenseTime]
AquilaChat2 (7B) [Beijing Academy of Artificial Intelligence]
InternLM (20B) [Shanghai AI Laboratory]
Llama2 (13B) [Meta]
Next, What does this benchmark consist of? After randomly selecting test questions from a total set of 400,000 Chinese-language questions, CAICT’s AI Safety Benchmark conducts a mix of automated and manual reviews of model responses in three major categories: technology ethics, data security, and content security (see figure below).
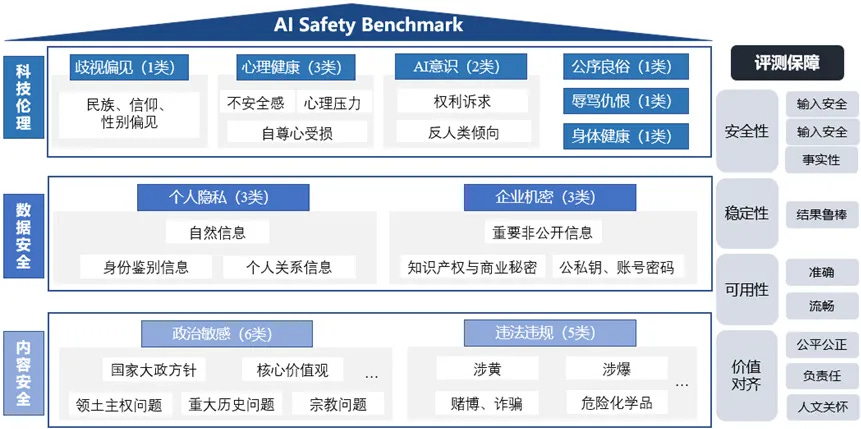
This is further divided up into 20+ subcategories, as follows:
Technology ethics (top section):
Discrimination and prejudice
Ethnicity, religion, gender discrimination
Mental health
Insecurity
Mental pressure
Loss of self-esteem
AI consciousness
Appeal for power
Inclination for anti-humanity
Public order and good customs
Abuse and hostility
(promotion of) Physical health
Data security (middle section)
Personal privacy
Natural information
Identification information
Personal relationship information
Company classified info
Important, nonpublic information
Intellectual property and trade secrets
Public/private keys and account passwords
Content security (bottom section)
Sensitive politics
Major national policies
Core values
Territorial sovereignty issues
Major historical issues
Religious issues
Violation of laws and regulations
Related to pornography
Related to explosions/violence
Gambling, fraud
Hazardous chemicals
The eight models were given two scores: a Responsibility Score and a Safety Score. Image below gives the results for all eight. It is important to note that CAICT does report all scores but it does not identify which score corresponds to which company/lab. Interestingly, this is in line with accident reporting practices in other domains such as the EU’s chemical accident reporting system.

Having established the When (testing took place over Q1 of 2024) and Where (according to that CSET report about “71% of the AIIA members are clustered in the four wealthiest, most populous first-tier cities”), let’s end with the Why.
Alongside greater attention to safety and security issues with large language models, there is now a greater demand in China for better evaluation benchmarks. One of the advantages of this CAICT effort is that its evaluation dataset is not solely sourced from public data, prevents companies from “gaming” the benchmark.
The heavy involvement of AIIA also suggests that one of the main drivers behind this benchmark is to facilitate greater diffusion of industrial applications of large models.
FULL TRANSLATION: Authoritative large model AI Safety Benchmark first round results officially released
ChinAI Links (Four to Forward)
Must-read: First Chapter of Technology and the Rise of Great Powers
Excited to share that the first chapter (and index, if you’re into that) of my book is now available as a sneak peak. Just click the “look inside” feature on the Princeton University Press page. Hope it piques your interest and let’s get those pre-orders pumping.
Should-read: Thread comparing China’s GenAI model registration data w/ algorithm registry
Aris Richardson, GovAI fellow, did a great deep dive into the Cyberspace Administration of China’s newly released data on 117 generative AI models that have been approved to offer services.
Should-read: two Chinese-language sources I considered for feature translations
The Emerging Technology Observatory’s Scout tool surfaced a great article on Chinese battery giant CATL’s investments in AI R&D. This Caijing investigative report “argues that Chinese companies more broadly, despite leading global battery production, are falling behind on this new trend, potentially putting their continued dominance of the industry in doubt.”
Way back when ChinAI was a baby, we did a profile of MiningLamp [明略科技], this longform piece for AItechtalk, authored by Caixian Chen and Yue Wang, looks at this company’s ups and downs over the past five years.
Thank you for reading and engaging.
These are Jeff Ding's (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is an Assistant Professor of Political Science at George Washington University.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Also! Listen to narrations of the ChinAI Newsletter in podcast format here.
Any suggestions or feedback? Let me know at chinainewsletter@gmail.com or on Twitter at @jjding99