


ChinAI #296: DeepSeek goes left, ModelBest goes right
Greetings from a world where…
the Netflix show Man on the Inside is criminally underrated
…As always, the searchable archive of all past issues is here. Please please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors).
Feature Translation: DeepSeek goes left, ModelBest goes right
Context: Currently, there are three groups of runners in the large model race. The first pack tries to follow OpenAI’s footsteps in building foundation models with larger and larger parameters by throwing more and more computing power at the problem. The second group pivots to large model applications, as they can’t burn through money to keep up. The third pack of racers might be the most interesting: they are trying to create more efficient large models from scratch by squeezing every ounce out of limited computing power.
The subjects of this week’s feature translation (link to original AItechtalk article) are two Chinese companies in this third group: DeepSeek and ModelBest [面壁智能]. They differ from the other promising Chinese start-ups: the “six little dragons” (Zhipu, MiniMax, Moonshot, Baichuan, 01.Ai, and Stepfun), which have mostly tried to follow OpenAI’s approach.
Key Takeaways: Even though they are both trying to make LLMs more “efficient”, they are taking two very different approaches. What makes ModelBest different from DeepSeek?
DeepSeek’s main efficiency innovations are in the training phase. They trained a Mixture of Experts (MoE) model from scratch and also used multi-head latent attention (MLA) technology. However, as industry practitioners tell AItechtalk, this is a solution optimize for “large cluster training and large cluster deployment services, using the cloud to provide user services” (emphasis mine).
In contrast, ModelBest’s efficiency innovations are in the inference (deployment) phase. Its MiniCPM model “optimizes the model training technology to make the model knowledge density higher, and then defeats the large parameter model with small parameters. The MiniCPM series of end-side models can also be run locally and directly on various end-side devices, providing intelligent capabilities equivalent to cloud APIs. DeepSeek has not yet provided a solution for the end-side scenarios that ModelBest focuses on.”
ModelBest founder Zhiyuan Liu proposes a Densing Law for large models, which tracks the continuous increase in the “density” [密度] of the capabilities of large models, which refers to how, over time, the same level of performance can be achieved with fewer parameters.
For example: In February 2024, a model with 2.4 billion parameters could achieve the capabilities of GPT-3 (released in 2020 with 175 billion parameters)
According to this Densing Law: “Every 3.3 months (about 100 days) the parameters a model needs to achieve the same capability decreases by half.”
ModelBest defines “capability density” as: “the ratio of the effective parameter size of a given LLM to the actual parameter size. If, for example, a 3B model can achieve the performance of a 6B reference model, then the capability density of this 3B model is 2 (6B/3B).” The graph below shows that capability density has been steadily increasing over the past two years.
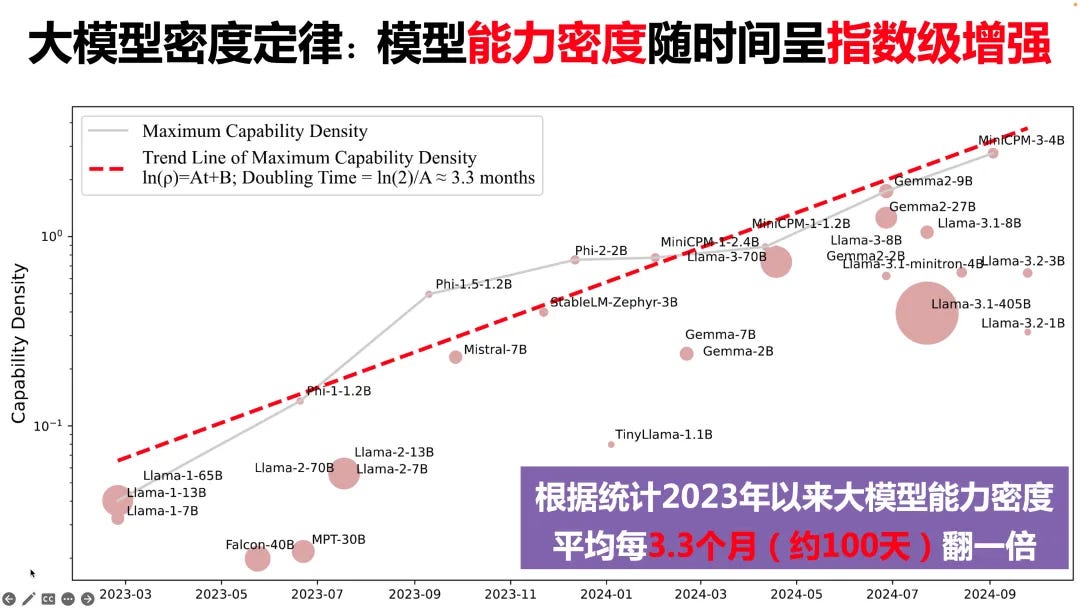
If this Densing Law holds, ModelBest believes its bet on end-side models will pay off. The idea here is that if smaller models are deployed on the edge, then end-side compute (e.g., the chips in mobile phones) can handle the calculations and computations necessary to run AI applications (instead of meeting those demands using the cloud).
Liu told AItechtalk, “The capabilities of a 13B model can obviously be achieved with a 2B model, and it can run very fast on the client side, so there is no need to test it or send requests. Large models are computationally intensive tasks. From the perspective of sustainable development and actual implementation, it is obvious that the computing power on the client side has not been set loose at all, so the results of MiniCPM are very likely to be in line with the future direction. Moreover, not all demands must use GPT-4; sometimes GPT-3 can also meet them.”
One potential bottleneck is end-side computing power. In other words, can an iPhone support a 7B model for longer than 2 hours? Han Xu, chief researcher of ModelBest, is optimistic about future developments: “First, chips are undergoing high levels of development. The latest chips can already support models with tens of billions of parameters. Secondly, model training technology is improving. Models with two or three hundred billion parameters can also reach the level of GPT-3.5. The key issue is how to connect chips and model training, which requires optimization. However, this block of technologies is no longer a problem. We just need to wait for the opportunity.”
FULL TRANSLATION: Hidden players of large models come to the table: DeepSeek goes left, ModelBest goes right
ChinAI Links (Four to Forward)
Must-read: How Bad is Bypassing Paywalls
As someone who does this a lot and as someone who appreciates paying subscribers who support this work, this article by Ben Lindbergh for The Ringer was the most thoughtful thing I read this past week.
Should-read: ChinAI #199 profile of ModelBest
ChinAI covered Modelbest’s approach way back in October 2022, before it was cool to report on smaller LLMs. Full translation has some interesting details about how their Chinese name is inspired by Cixin Liu’s Three Body Problem.
Should-read: The US Army needs less good, cheaper drones to compete
The Economist makes a smart point about drone acquisition strategies. H/t to Jackie Schneider for sharing. See her thread for more reading recommendations on this thread.
Should-read: Inadvertent Expansion
My GW colleague Nick Anderson just published a fascinating book (Cornell University Press) on inadvertent territorial expansion — actions that were neither intended nor initially authorized by state leaders:
Through cases ranging from those of the United States in Florida and Texas to Japan in Manchuria and Germany in East Africa, Anderson shows that inadvertent expansion is rooted in a principal-agent problem…Accentuating the influence of small, seemingly insignificant actors over the foreign policy behavior of powerful states, Inadvertent Expansion offers new insights into how the boundaries of states and empires came to be and captures timeless dynamics between state leaders and their peripheral agents.
Thank you for reading and engaging.
These are Jeff Ding's (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is an Assistant Professor of Political Science at George Washington University.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Also! Listen to narrations of the ChinAI Newsletter in podcast format here.