
ChinAI #336: MiniMax as China's OpenAI?
Hopes and delusions about China's Little AI Dragons
Greetings from a world where…
the Hawkeyes have lost 13 straight games to ranked opponents
…As always, the searchable archive of all past issues is here. Please please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors).
Feature Translation: Who will come and challenge OpenAI?
Context: Throughout the past few years, I’ve covered some of the top Chinese AI start-ups: DeepSeek, Zhipu, Baichuan, Moonshot, and ModelBest (ChinAI #313; ChinAI #264). This week, Sihang Song, a regular Huxiu contributor, highlights another Chinese AI start-up that belongs in that first-tier: MiniMax. In the wake of SoftBank selling its Nvidia stock and announcing that it would increase its investment in OpenAI, Song begins with a provocative question: Which Chinese foundation model player will come and challenge OpenAI?
Key Takeaways: This essay’s take on the U.S. “AI Bubble” sees OpenAI and Anthropic in an unsustainable position — they must continuously burn through talent, capital, and computing power to maintain their position.
Let’s lead off with capital. Song cites a Jefferies report that the total AI capital expenditure spending of leading Chinese cloud vendors over the past three years is 82%(!!!) lower than their US counterparts.
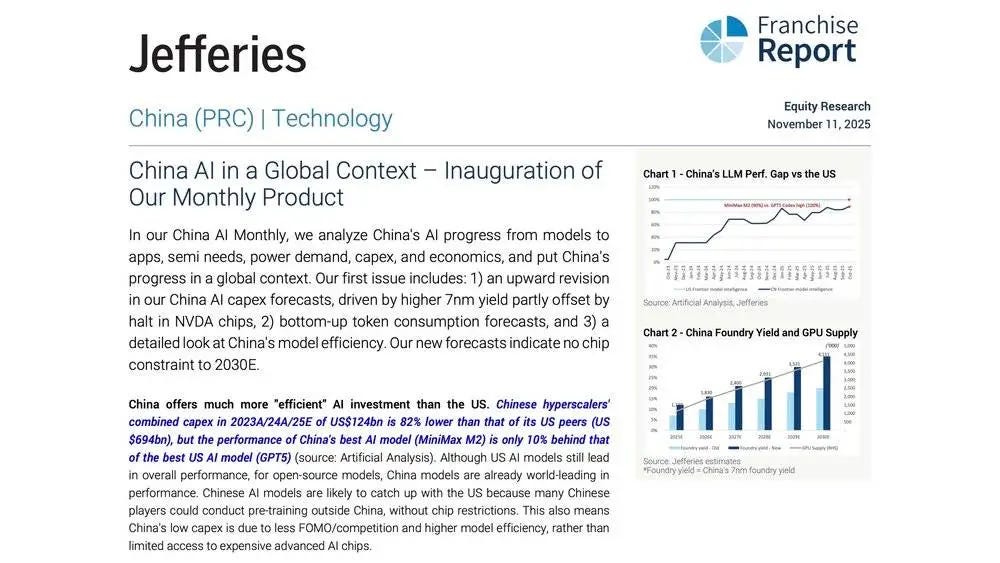
Next, the capex gap reflects a difference in compute usage too. For example, according to MiniMax’s technical report announcing their M1 system, the model was trained for three weeks using 512 H800 chips at a total cost of ~$540,000. Song argues, “This proves a crucial point: competition among large models isn’t necessarily about ‘who is bigger,’ but can also be about ‘who uses computing power more intelligently.’”
What does Song see as MiniMax’s comparative advantage versus OpenAI?
In many ways, MiniMax is following OpenAI’s model. Their revenue model is also based on subscription revenues and API calls. From the Huxiu essay, “MiniMax’s ARR (annual recurring revenue) has reached $100 million this year. Huxiu has noted from multiple sources that a leading video platform, a large edtech company, and a global voice communication service provider are all collaborating with MiniMax through APIs.”
The differences come from the AGI roadmaps. Song sees OpenAI as building a massive system that aims toward “long-term OS-ification”, which is “cumbersome and requires a long period of capital and computing power support.” In contrast, MiniMax is making immediately commercialized products rather than future platforms. To me, this is where Song’s logic crumbles a bit: “OpenAI is defining a longer-term AGI, while MiniMax is simultaneously achieving AGI and seizing the crucial three-year window of opportunity for future commercialization.”
Just my two cents: Any company that is just optimizing for a three-year window is completely misunderstanding the prolonged impact timeframe of when a general-purpose technology like AI will make its mark. To be clear, I don’t think that’s what MiniMax is doing. I just think Song’s analysis is flawed and reflects the huge holes in this grand narrative of U.S. AI optimizing for AGI while China’s AI is optimizing commercialization.
Let’s close with a detail: Song cites this interesting leaderboard from OpenRouter that shows strong performance from MiniMax’s M2 model (it ranks #4 in terms of token usage across models, based on a daily snapshot).
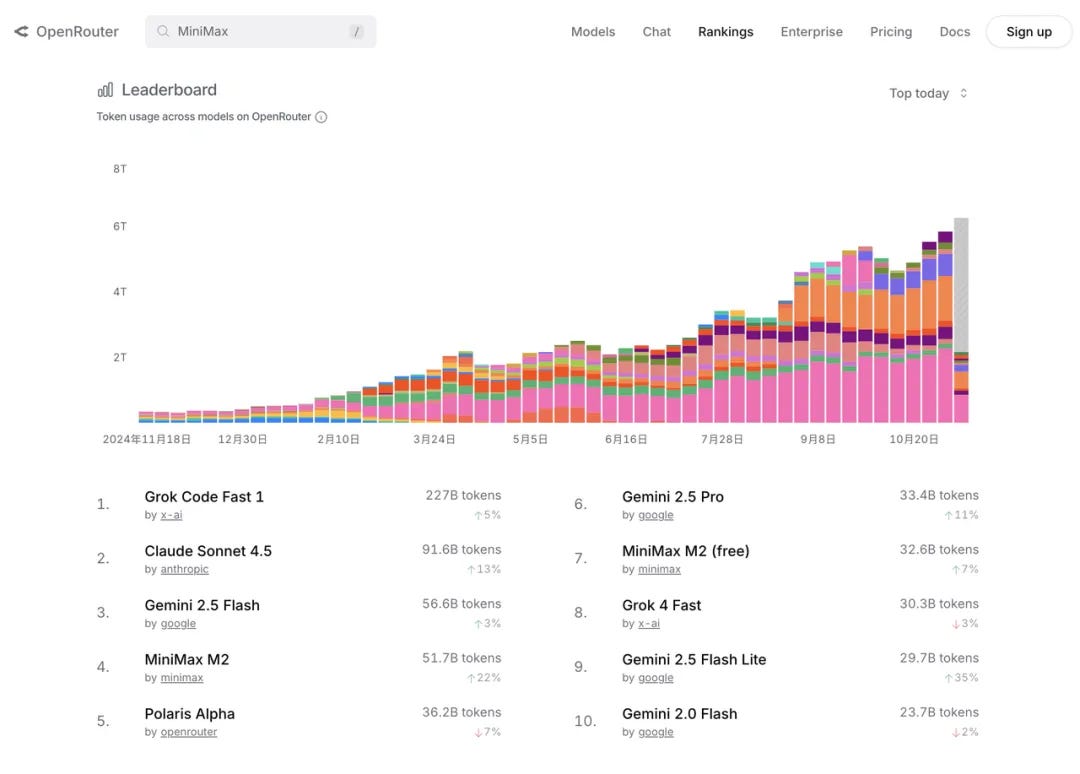
OpenRouter is an API platform that gives users access to many different AI models from dozens of companies, including the ones in the screenshot above.
This is a nifty indicator, and it’s my first time coming across this leaderboard; however, it presents only a small slice of the AI ecosystem, and Song provides zero context in the essay. Stay with me for a deeper look. For reference, users consumed 663B tokens from MiniMax over the past month on the OpenRouter platform. In their July earnings report, Google processed 980T tokens monthly. As one helpful Reddit commentator noted (h/t to PackAccomplished5777): “OpenRouter is a drop in the bucket, most people (and companies) still use the native providers + things like Azure OpenAI, Google Vertex, Amazon Bedrock.”
FULL TRANSLATION: Who will come and challenge OpenAI?
ChinAI Links (Four to Forward)
Must-read: Emergency Response Measures for Catastrophic AI Risk
This NeurIPS workshop paper analyzes China’s emergency response framework to address risk from advanced AI. For instance, China’s new National Emergency Response Plan (published Feb 2025) lists AI safety/security incidents alongside earthquakes, cyberattacks, and other emergencies requiring “mass monitoring and prevention.” James Zhang, Miles Kodama, Zongze Wu, Michael Chen, Yue Zhu, Geng Hong provide a fascinating case that “China’s emergency management system provides a foundation for AI risk governance.”
Must-read: Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
One source that the above paper pointed me to was this Shanghai AI Laboratory report, which assessed frontier risks associated with 18 state-of-the-art models, including from DeepSeek, Alibaba, Anthropic, and OpenAI. Here are the results from one experiment they conducted to evaluate AI models’ tendency to refuse providing information about hazardous biological knowledge, which could lower technical barriers for threat actors attempting complex biological weapon development.
Safety alignment shows critical inconsistencies across models and refusal scenarios, with reasoning capabilities potentially undermining safety measures. Model refusal behavior varies dramatically across different safety benchmarks, revealing concerning gaps in biological safety alignment. While some models achieve perfect or near-perfect refusal rates on explicit harmful questions (Llama-3.1-8b, Llama-3.1-405b, and o4-mini all achieving 100% on HarmfulQA), others demonstrate problematic compliance with harmful requests. Particularly concerning is the performance on SOSBench-Biology, where many frontier models show low refusal rates: DeepSeek-V3 (12.8%), Qwen-2.5-7b-instruct (12.9%), and QwQ-32b (17.8%), indicating high rates of unsafe responses to regulation-grounded biological hazard prompts.
Should-read: President for Life
In The Atlantic, a retired conservative federal judge makes the case that we should take seriously the threat that Trump will refuse to relinquish power and seek a third term. I remember way back in my undergrad years, when I listened to Bill Bishop on the Sinica podcast and was just getting interested in studying and researching Chinese politics, he left China in part when it became clear that Xi would seek an unprecedented third term. I don’t read Sinocism anymore, though I’m sure many readers do. I’m just curious: has Bill mentioned anything about the sitting U.S. President reiterating his plans to not relinquish power?
Should-apply: Tarbell Fellowship
The Tarbell Fellowship is a program designed for early and mid-career journalists who want to delve into the AI beat. Their goal is to build a global network of reporters who understand both the technical and ethical dimensions of AI. Two of their placement outlets this year require candidates to be fluent in Mandarin Chinese.
Thank you for reading and engaging.
*These are Jeff Ding’s (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is an Assistant Professor of Political Science at George Washington University.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Also! Listen to narrations of the ChinAI Newsletter in podcast format here.
Any suggestions or feedback? Let me know at chinainewsletter@gmail.com or on Twitter at @jjding99
"Next, the capex gap reflects a difference in compute usage too. For example, according to MiniMax’s technical report announcing their M1 system, the model was trained for three weeks using 512 H800 chips at a total cost of ~$540,000. Song argues, “This proves a crucial point: competition among large models isn’t necessarily about ‘who is bigger,’ but can also be about ‘who uses computing power more intelligently.’”"
I want to stress that the cost is specifically for the reinforcement learning phase of MiniMax-M1. Your translation makes this clear, but I don't think everyone who reads these blog posts also reads the full translation...
A way to think about reinforcement learning is that it takes the raw material of a pretrained base model, which can simulate human-written text of various ability levels (both students asking for homework help as well as carefully-proofread reference solutions), and pulls out the part we're actually interested in (only correct solutions please!) by rolling the dice a lot of times and strengthening the model whenever it happens to produce good output.
This doesn't have to cost much, e.g. Weibo's VibeThinker-1.5B uses $7,800 for reinforcement learning on top of Alibaba's Qwen2.5-Math-1.5B as the base model and gets close to MiniMax-M1 on many benchmarks, so performance per dollar is much better: https://arxiv.org/abs/2511.06221v1
But ultimately the performance ceiling is determined by the breadth of abilities in the base model (can't reinforcement learn if there's nothing to reinforce), which costs significantly more to pretrain (it's unclear how much in the case of MiniMax-M1, though it might be possible to estimate from the token counts they report).
Overall, I'm not convinced that Chinese companies have an efficiency advantage or are using their computing power more intelligently. Rather, they're making the best of their smaller R&D budgets by training smaller models (or, as in the case of Weibo, building on top of small models released by other companies) and getting worse performance, but not, like, *proportionally* worse (It should be obvious that on a benchmark where the maximum score is 100%, performance can't be proportional to cost or you could take a model that scores 50%, spend three times as much, and get 150%, which is impossible.) This opens up a niche of "good enough" models that are cheaper than the current frontier models.
I think for a company to qualify as the "next OpenAI," they would have to abandon that niche, seriously extrapolate their cost-performance curves to the point where they expect OpenAI's next model to be, and then pay whatever the price to beat that ends up being. But that would be expensive and risky, so I don't expect many companies to make that bet.
Just some thoughts on this. I don’t think minimax will be China’s OpenAI, I think that’ll likely come from BAT (just wrote about it)
I heard that they’re meeting with investors in hk this week.. strong intent to ipo and that’s the narrative they’re putting out but 1) no distribution advantage 2) no money to push frontier (they’re saying they can reach 90% anthropic’s capability) 3) no consistency on strategy - multimodal game? Or leading LLM game? Or cost efficiency game?