


ChinAI #95: Introducing PaperWeekly — Let's Read it Together
Plus, Jeff Jots on his article on local AI policy in "dark horse" clusters (Hefei, Hangzhou)
Greetings from a land where even the homecoming king cries…
…as always, the archive of all past issues is here and please please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay support access for all AND compensation for awesome ChinAI contributors).
Browsing PaperWeekly Together
One of the issues I (and a lot of folks in this space, I think) struggle with is how much technical knowledge we need to accumulate. As someone without a technical background, I’m always faking’ it until I make it. But what does making it look like?
While technical fluency is the holy grail, I think folks who study politics of tech can reasonably shoot for better levels of technical literacy. Open source courses, playing around with trying to implement some very simple ML techniques (like my attempt to build a classifier for Taylor Swift songs), and weekly newsletters that keep you updated on the state of the AI field are all helpful. Thebatch, deeplearning weekly, and my personal favorite — Jack Clark’s Import AI — are example resources.
This week we’re going to look at one Chinese newsletter/platform called Paperweekly that’s also in this mold. I think it’s a really interesting model for up-skilling/keeping updated on ML research, and for those interested in China’s AI landscape, one advantage of following Paperweekly is you can double dip and brush up on both your Mandarin and code literacy. So, let’s read it together…
Here’s what my version of the homepage looks like:
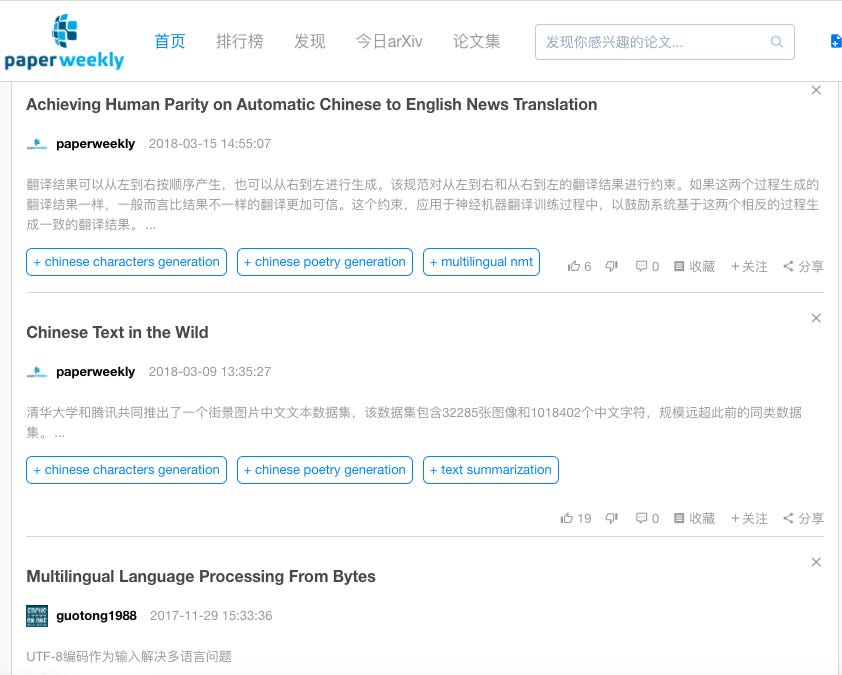
To access the site you have to give an email address and then wait 24 hours for a check. When you register, you can list your interests. I put down NLP, so the homepage gives me recommended arxiv articles on NLP that I can read. I scrolled down a little to some of the more well-known pieces in this field — the first one in the screenshot above is the well-known Microsoft paper on NMT achieving human parity in Chinese-English news. Note that the site-runners recommend some articles, but most recommendations come from users (like the third one in the screenshot). Let’s click on the 2nd article in the screenshot — “Chinese Text in the Wild”:

There’s an abstract summary (with authors, date, arxiv link) in the main body. Then, the right column has (from top to bottom): the open source PyTorch implementation of the code, links to collections of articles that feature this article, and also links to related articles.
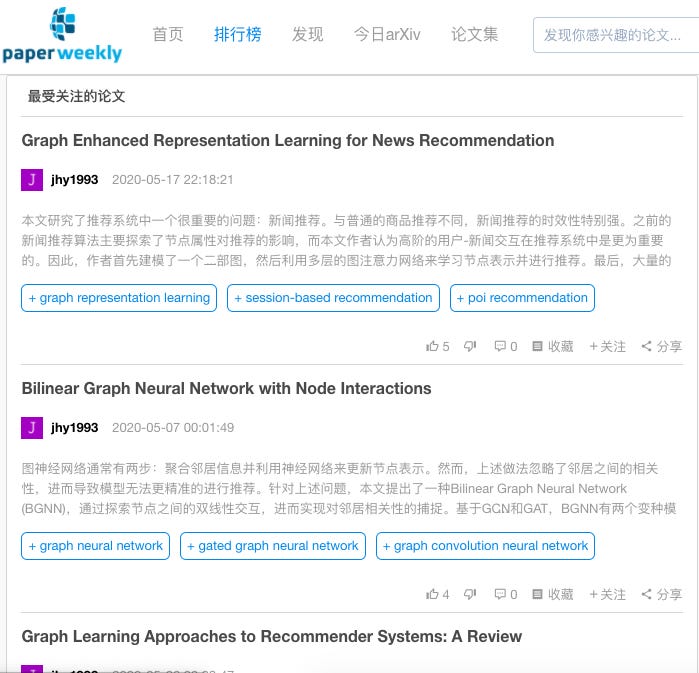
Second section is the paper rankings. Let’s say I wanted to see the most viewed papers of all time under the tab of data mining:

I can also just get the data mining papers that received the most views from just this past month:
Next is the “Discover” tab, which gives notes/explainers on different ML subjects. I sorted by NLP-related subjects. The first one that comes up explains the mechanics of a “billingual expert model” — basically the construction of a model to find errors in neural machine translation. I believe its’s trying to break down this article accepted to AAAI 2019.

The next tab is “today’s arxiv” which gives me five arxiv articles (I think also targeted at NLP since that was what I selected as my interest) that I can recommend or not. Finally, the last tab (论文集) lets people build collections of articles around a particular topic. Some of the most popular are collections of papers on qa & chatbots, attention, GANs, etc.
Feature Translation — A Complete Explanation of Masking in NLP
So, let’s take a peek into an example Paperweekly article. We’re all intensely familiar now with the role of masks in preventing covid transmission, but what about the role of masks in NLP models? (how’s that for a transition sentence that endeavors to make really nitty gritty technical details relatable to the average Jeff?)
Context: Short and effective explainer written on May 8 by Hai Chenwei, a Master’s student at Tongji University. It’s a nice simple explainer of the function of masking, with summaries of the key articles, figures of Chinese-language use cases, and example code implementations.
Key takeaways: Masking is a function that does two main things:
1) Helps NLP models handle input sequences of variable length (e.g. really short sentences). It goes through how masking differs in RNNs vs. attention mechanisms. For a really good explainer of the concept of “attention” in neural machine translation, see this article.
2) Prevent the disclosure of the (Accurate) Label. “In language models, it is often necessary to predict the next word from the previous word, but if you want to apply ‘self attention’ in LM (language models) or use contextual information at the same time, you need to use a mask to ‘cover’ so as to prevent disclosing the label information that you want to predict. Different papers have different masking methods.” Hai then goes through how the masking methods differ across transformers, BERT, and XLNet.
We’ll definitely be coming back to Paperweekly in the upcoming weeks. If folks do some exploring of this platform their own and want to contribute to translations, let me know!
FULL(ish) TRANSLATION: A Complete Explanation of Masking in NLP
Jeff Jots
Last week Nesta published a collection of essays (link downloads a PDF) on China’s “AI Powered State.” I wanted to give a quick breakdown of my essay in this collection, titled “Promoting Nationally, Acting Locally: China’s Next Generation AI approach.” Hopefully we’ll come back to this and give some breakdowns on the other essays which are all well-worth reading. In my article, my goal was to investigate why Hangzhou and Hefei, which often rank as top AI clusters alongside the first-tier cities (BJ, SZ, SH, GZ), have built such successful industrial ecosystems.
The key point: Efforts of local governments play a crucial role — arguably more important than the central government — in fostering AI development. This is the case with overall S&T policy too. I write, “Provincial and local governments play an outsized role – one only increasing in significance – in implementing innovation policy. Their proportion of China’s overall fiscal expenditures on science and technology rose from 48 per cent during 2007–2011 to 59 per cent in 2015–2016. (ref. 4)”
Key Similarities between Hangzhou and Hefei:
Both Hangzhou and Hefei have a key ‘anchor tenant’ tech company (Alibaba for Hangzhou and iFlytek for Hefei) and an elite university (Zhejiang University for Ali and USTC for iFlytek) that glue the ecosystem together
Both had established plans to spur AI development before the July 2017 national AI plan was announced. I examine Hangzhou Future Sci-Tech City’s AI Town initiative and Hefei’s China Speech Valley initiative. In places where there is already a decently strong technology base, anchored by players mentioned above, then local initiatives like S&T parks can help circulate knowledge and boost agglomeration effects.
Key Differences
Compared to Hangzhou, China Speech Valley’s international linkages are not as strong and there is less appeal for graduate returnees to work in Hefei. Overall, Hangzhou boasted the highest growth in attracting returning graduates from international universities from 2017 to 2018, according to a report by recruitment site Boss Zhipin.
Partly due to the above point, Hangzhou has a more comprehensive coverage of AI subdomains compared to Hefei, which is specializing in intelligent speech.
Dive really deep
One of the main issues with doing research on AI policy is trying to get to the substance behind some of the outlandish announced figures reported in the media (anybody remember the over-hyping of Tianjin’s $15 billion AI fund?). Well, Hangzhou AI Town published an audit report of its 2019 spending, so we can actually get a sense of project-level spending when we get really local.
Per the report: Hangzhou AI Town disbursed 43 million RMB in funding in 2019, separated into research and development (R&D) funds, subsidies for office fees and cloud services funds. Across the three categories, the 123 accepted project proposals spanned an extensive range of subdomains (from sign language translation using computer vision to predictive analytics of smart city data) and parts of the AI stack (from open source software to end devices). Alibaba Cloud was the sole supplier or co-supplier for 25 of the 27 projects in the cloud services category.
Read the full article in the Nesta collection of essays.
ChinAI Links (Four to Forward)
Must-read: Data Security and U.S.-China Tech Entanglement
Was doing some research on data security standards this week, and came across this really fantastic Lawfare article by Samm Sacks I had missed from last month. It provides a framework for how US should approach complicated data security issues related to China. It incorporates a really rare sort of triple-threat combination of info from contacts on ground, technical chops, and smart strategy. Based on her full testimony before the Senate Judiciary Committee:
Must-read: Policy.AI
Curated by Rebecca Kagan, a no-nonsense, info-packed, comprehensive newsletter by CSET that gives biweekly updates on AI, emerging technology & security policy. Caught up on the May 13 issue recently, and here’s some nuggets you can expect in each issue:
“Machine Learning Spotlight — Limitations of AI COVID-19 Diagnostic Tools: Preliminary research suggests that most models using AI for COVID-19 diagnosis and prognosis are at high risk of bias and likely misleading. The researchers reviewed 31 models that use AI for online diagnosis, diagnosis based on CT scans and case prognosis prediction. According to their assessment, the reported performance of all 31 models was “probably optimistic.” Given the lack of external validation of most models, the authors recommend against relying on any current AI-based COVID-19 diagnostic tools. More:Google’s Medical AI Was Super Accurate in a Lab. Real Life Was a Different Story. | AI Software Gets Mixed Reviews for Tackling Coronavirus”
Also includes an “In Translation” section which includes CSET’s translations of important foreign language documents on AI. Waaay back in March 2018, the first issue of ChinAI featured my excerpted translation of an AI Standardization White Paper. Now, CSET has published a full translation, edited by Ben Murphy, that makes some really valuable info more accessible (See, for example, p. 37 breakdown of ISO/IEC JTC 1 and AI standardization-related subcommittees; and p. 74-75 on use cases of iFlytek’s intelligent speech tech in high school/college exam entrance exams)
Should-read: China NewSpace Newsletter
I’m really excited about others adopting the ChinAI model to other topics. Check out Cory Fitz’s new newsletter on Newspace. Here’s the description: “I created this newsletter because two of my passions, China and space, have finally come together. The private space industry in China is young and growing rapidly; it was only in 2014 that the State Council began encouraging private investment in space…To better understand these developments, the China NewSpace newsletter will bring you translations of interesting Chinese-language blog posts, articles, etc…as well as a roundup of news in the Chinese private space industry.”
Should-read: A Forgotten Story of Soviet AI
It’s funny — I first came across this piece via a Chinese translation of a platform I follow. Sergei Ivanov retells a forgotten story of Soviet AI dating back to 1955, through the lens of Alexander Kronrod who founded the first AI lab in the USSR.
Thank you for reading and engaging.
These are Jeff Ding's (sometimes) weekly translations of Chinese-language musings on AI and related topics. Jeff is a PhD candidate in International Relations at the University of Oxford and a researcher at the Center for the Governance of AI at Oxford’s Future of Humanity Institute.
Check out the archive of all past issues here & please subscribe here to support ChinAI under a Guardian/Wikipedia-style tipping model (everyone gets the same content but those who can pay for a subscription will support access for all).
Any suggestions or feedback? Let me know at chinainewsletter@gmail.com or on Twitter at @jjding99